
一、设计目的
通过设计、编写调试一个词法分析程序,加深对词法分析原理的理解,并掌握对程序设计语言源程序进行扫描过程中将其分解为各位单词符号的词法分析方法。
二、设计内容
编写一个词法分析程序,从输入的源程序中识别出各个具有独立意义的单词,即基本字、标识符、常数、运算符、分隔符五大类,并依次输出各个单词的内部编码及单词符号自身值,遇到错误时可显示“error”,然后跳过错误部分继续显示。
1.词法分析器的功能和输出形式
词法分析器的功能是输入源程序,输出单词符号。词法分析器的单词符号常常表示成以下的二元组(单词种别编码,单词自身值)。本题目中可采用一类符号一个种别编码的方式。
2.单词的词法规则
<标识符>→ <字母><字母数字串>
<字母数字串>→<字母><字母数字串>|<数字><字母数字串>|<下划线><字母数字串>|ε
<无符号整数>→ <数字><数字串>
<数字串>→<数字><数字串>|ε
<加法运算符>→ +
<减法运算符>→ -
<大于关系运算符>→ >
<大于等于关系运算符>→ >=
3.超前搜索方法
词法分析时,常常会用到超前搜索方法。如当前待分析字符串为“a>=”或“a>b”,当前字符为’>’,此时,分析器倒底是将其分析为大于关系运算符还是大于等于关系运算符呢?显然,只有知道下一个字符是什么才能下结论。于是分析器读入下一个字符‘b’,这时可知应将’>’解释为大于运算符。但此时,超前读了一个字符‘b’,所以要回退一个字符,词法分析器才能正常运行。在分析标识符,无符号整数等时也有类似情况。
4.编程思路
以满足以上词法规则要求的 C 语言子集的源程序作为词法分析程序的输入。在词法分析中,自头文件开始扫描源程序字符,一旦发现符合单词定义的字符串时,将它翻译成固定长度的单词内部表示,并查填适当的信息表。经过词法分析后,源程序字符串被分解为具有等长信息的单词符号串,并产生两个表格:常数表和标识符表,他们分别包含了源程序中的所有常数和标识符。
5.单词种别编码要求
识别保留字:if int for while do return break continue,单词种别编码为 1。
分隔符: , ; { } ( ) 单词种别编码为 2。
运算符:+ - * 、 = 种别编码为 3。
关系运算符:> < >= <= == != 种别编码为 4。
标识符:种别编码为 5。
常数为无符号整型数,种别编码为 6。
三、功能扩充
若考虑程序中的注释/*......*/,程序如何处理?
四、算法设计
1.单词分类表
| 单词符号 | 种类 | 种类码 | 单词符号 | 种类 | 种类码 |
| if | 关键字 | 1 | + | 运算符 | 3 |
| int | 关键字 | 1 | - | 运算符 | 3 |
| for | 关键字 | 1 | * | 运算符 | 3 |
| while | 关键字 | 1 | / | 运算符 | 3 |
| do | 关键字 | 1 | > | 关系运算符 | 4 |
| return | 关键字 | 1 | < | 关系运算符 | 4 |
| break | 关键字 | 1 | >= | 关系运算符 | 4 |
| continue | 关键字 | 1 | <= | 关系运算符 | 4 |
| , | 分隔符 | 2 | == | 关系运算符 | 4 |
| ; | 分隔符 | 2 | != | 关系运算符 | 4 |
| { | 分隔符 | 2 | 标示符 | 标示符 | 5 |
| } | 分隔符 | 2 | 整形常量 | 整形常量 | 6 |
| ( | 分隔符 | 2 | /* | 注释 | 7 |
| ) | 分隔符 | 2 | */ | 注释 | 7 |
2.状态转化图
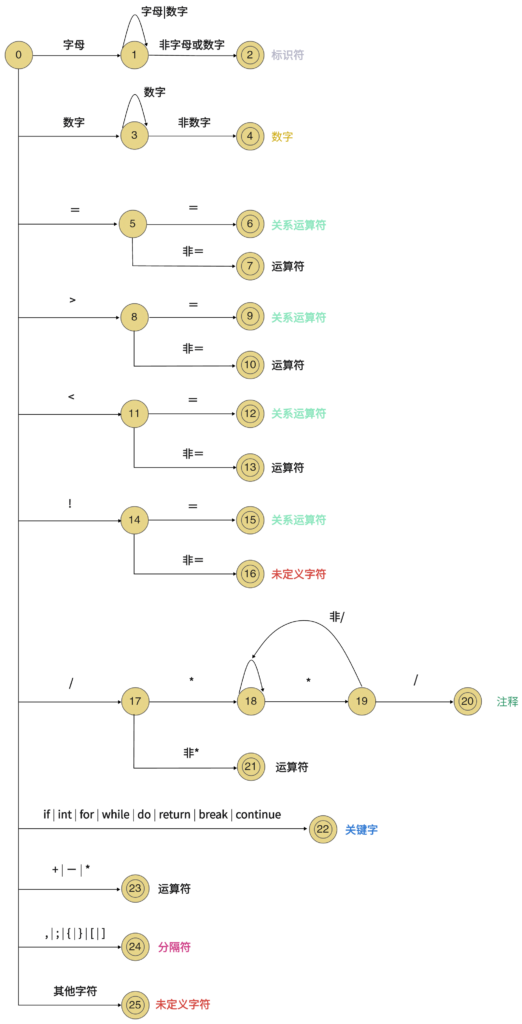
3.算法流程图
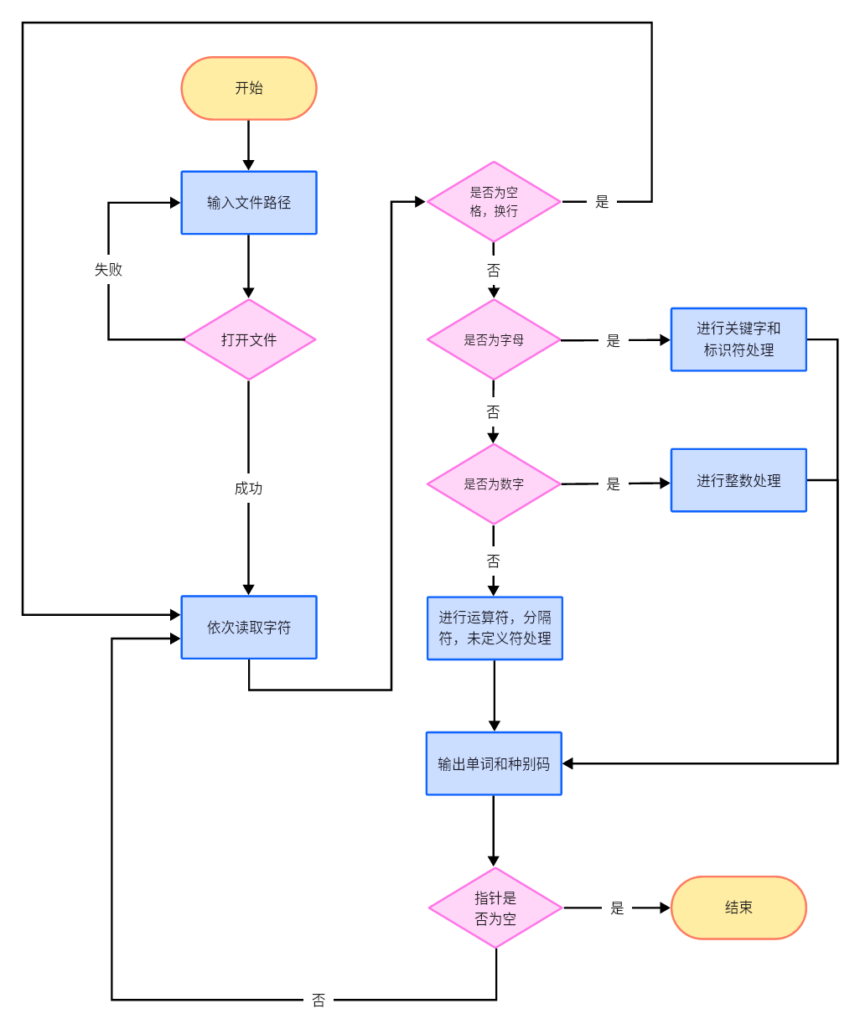
4.程序代码
/***********************************************
* 词法分析器
* 编译环境:MinGW32
***********************************************/
#include <iostream>
#include <string>
#include <Windows.h>
#include <stdio.h>
#include <ctype.h>
using namespace std;
/* 单词编码 */
enum TokenCode
{
/*未定义*/
TK_UNDEF = 0,
/* 关键字 */
KW_IF, // if关键字
KW_INT, // int关键字
KW_FOR, // for关键字
KW_WHILE, // while关键字
KW_DO, // do关键字
KW_RETURN, // return关键字
KW_BREAK, // break关键字
KW_CONTINUE, // continue关键字
/* 运算符 */
TK_PLUS, // +加号
TK_MINUS, // -减号
TK_STAR, // *乘号
TK_DIVIDE, // / 除号
TK_ASSIGN, // =赋值运算符
/* 关系运算符 */
TK_EQ, // ==等于号
TK_UEQ, // !=不等于号
TK_LT, // <小于号
TK_LEQ, // <=小于等于号
TK_GT, // >大于号
TK_GEQ, // >=大于等于号
/* 分隔符 */
TK_OPENPA, //(左圆括号
TK_CLOSEPA, //)右圆括号
TK_OPENBR, //[左中括号
TK_CLOSEBR, //]右中括号
TK_BEGIN, //{左大括号
TK_END, //}右大括号
TK_COMMA, //,逗号
TK_SEMOCOLOM, //;分号
/* 常量 */
TK_INT, // 整型常量
TK_DOUBLE, // 浮点型常量
/* 标识符 */
TK_IDENT,
/* 注释*/
TK_PS
};
/******************************************数据结构*****************************************************/
TokenCode code = TK_UNDEF; // 记录单词的种别码
const int MAX = 8; // 关键字数量
int row = 1; // 记录字符所在的行数
string token = ""; // 用于存储单词
string keyWord[8] = {"int", "if", "for", "while", "do", "return", "break", "continue"}; // 存储关键词
/**********************************************函数*****************************************************/
/********************************************
* 功能:打印词法分析的结果
* code:单词对应的种别码
* token:用于存储单词
* row:单词所在的行数
*********************************************/
void print(TokenCode code)
{
switch (code)
{
/*未识别的符号*/
case TK_UNDEF:
SetConsoleTextAttribute(GetStdHandle(STD_OUTPUT_HANDLE), FOREGROUND_RED); // 未识别符号为红色
cout << '(' << code << ',' << token << ")" << "未识别的符号在第" << row << "行。" << endl;
return;
break;
/*关键字*/
case KW_IF: // if关键字
case KW_INT: // int关键字
case KW_FOR: // for关键字
case KW_WHILE: // while关键字
case KW_DO: // do关键字
case KW_RETURN: // return关键字
case KW_BREAK: // break关键字
case KW_CONTINUE: // continue关键字
SetConsoleTextAttribute(GetStdHandle(STD_OUTPUT_HANDLE), FOREGROUND_INTENSITY | FOREGROUND_BLUE); // 关键字为蓝色
cout << '(' << 1 << ',' << token << ")" << endl;
return;
break;
/* 运算符 */
case TK_PLUS: //+加号
case TK_MINUS: //-减号
case TK_STAR: //*乘号
case TK_DIVIDE: /// 除号
case TK_ASSIGN: //=赋值运算符
SetConsoleTextAttribute(GetStdHandle(STD_OUTPUT_HANDLE), 0x07); //运算符为白色
cout << '(' << 3 << ',' << token << ")" << endl;
return;
/* 关系运算符 */
case TK_EQ: //==等于号
case TK_UEQ: //!=不等于号
case TK_LT: //<小于号
case TK_LEQ: //<=小于等于号
case TK_GT: //>大于号
case TK_GEQ: //>=大于等于号
SetConsoleTextAttribute(GetStdHandle(STD_OUTPUT_HANDLE), 0x0A); //关系运算符为淡绿色
cout << '(' << 4 << ',' << token << ")" << endl;
return;
/* 分隔符 */
case TK_OPENPA: //(左圆括号
case TK_CLOSEPA: //)右圆括号
case TK_OPENBR: //[左中括号
case TK_CLOSEBR: //]右中括号
case TK_BEGIN: //{左大括号
case TK_END: //}右大括号
case TK_COMMA: //,逗号
case TK_SEMOCOLOM: //;分号
SetConsoleTextAttribute(GetStdHandle(STD_OUTPUT_HANDLE), FOREGROUND_INTENSITY | 0x0d); // 分隔符为粉色
cout << '(' << 2 << ',' << token << ")" << endl;
return;
break;
/* 常量 */
case TK_INT: // 整型常量
SetConsoleTextAttribute(GetStdHandle(STD_OUTPUT_HANDLE), 0x0e); // 常量为黄色
cout << '(' << 6 << ',' << atoi(token.c_str()) << ")" << endl;
return;
break;
/* 标识符 */
case TK_IDENT:
SetConsoleTextAttribute(GetStdHandle(STD_OUTPUT_HANDLE), FOREGROUND_INTENSITY); // 标识符为灰色
cout << '(' << 5 << ',' << token << ")" << endl;
return;
break;
/* 注释*/
case TK_PS:
SetConsoleTextAttribute(GetStdHandle(STD_OUTPUT_HANDLE), FOREGROUND_INTENSITY | FOREGROUND_GREEN); // 注释为绿色
cout << '(' << 7 << ',' << "\n" << token << "\n" << ")" << endl;
return;
break;
default:
break;
}
}
/********************************************
* 功能:判断是否是关键字
* MAX:关键字数量
* token:用于存储单词
*********************************************/
bool isKey(string token)
{
for (int i = 0; i < MAX; i++)
{
if (token == keyWord[i])
return true;
}
return false;
}
/********************************************
* 功能:返回关键字的内码值
* MAX:关键字数量
* token:用于存储单词
*********************************************/
int getKeyID(string token)
{
for (int i = 0; i < MAX; i++)
{ // 关键字的内码值为keyWord数组中对应的下标加1
if (token.compare(keyWord[i]) == 0)
return i + 1;
}
return -1;
}
/********************************************
* 功能:词法分析
* fp:文件指针
* code:单词对应的种别码
* token:用于存储单词
* row:单词所在的行数
*********************************************/
void lexicalAnalysis(FILE *fp)
{
char ch; // 用于存储从文件中获取的单个字符
while ((ch = fgetc(fp)) != EOF) // 未读取到文件尾,从文件中获取一个字符
{
token = ch; // 将获取的字符存入token中
if (ch == ' ' || ch == '\t' || ch == '\n') // 忽略空格、Tab和回车
{
if (ch == '\n') // 遇到换行符,记录行数的row加1
row++;
continue; // 继续执行循环
}
else if (isalpha(ch)) // 以字母开头,关键字或标识符
{
token = ""; // token初始化
while (isalpha(ch) || isdigit(ch)) // 非字母或数字时退出,将单词存储在token中
{
token.push_back(ch); // 将读取的字符ch存入token中
ch = fgetc(fp); // 获取下一个字符
}
// 文件指针后退一个字节
fseek(fp, -1L, SEEK_CUR);
if (isKey(token)) // 关键字
code = TokenCode(getKeyID(token));
else // 标识符
code = TK_IDENT; // 单词为标识符
}
else if (isdigit(ch)) // 无符号常数以数字开头
{
token = ""; // token初始化
while (isdigit(ch)) // 当前获取到的字符为数字
{
token.push_back(ch); // 读取数字,将其存入token中
ch = fgetc(fp); // 从文件中获取下一个字符
}
code = TK_INT; // 单词为整型
// 文件指针后退一个字节,即重新读取常数后的第一个字符
fseek(fp, -1L, SEEK_CUR);
}
else
switch (ch)
{
/*运算符*/
case '+':
code = TK_PLUS; //+加号
break;
case '-':
code = TK_MINUS; //-减号
break;
case '*':
code = TK_STAR; //*乘号
break;
case '/':
{
ch = fgetc(fp); // 超前读取'/'后面的字符
if (ch == '*') // /*注释开始
{
code = TK_PS;
token.push_back(ch); // 将'/'后面的'*'存入token中
while ((ch = fgetc(fp)) != EOF) // 读取注释内容
{
token.push_back(ch); // 注释内容存入token
if (ch == '*')
{
ch = fgetc(fp); // 超前读取'*'后面的字符
if (ch == '/')
{
token.push_back(ch); // 将'/'存入token
break; // 注释内容结束
}
else
{
fseek(fp, -1L, SEEK_CUR); // 将超前读取的字符重新读取
}
}
}
}
else
{ // / 运算符
code = TK_DIVIDE; // 单词为"/"
fseek(fp, -1L, SEEK_CUR); // 将超前读取的字符重新读取
}
}
break;
case '=':
{
ch = fgetc(fp); // 超前读取'='后面的字符
if (ch == '=') //==等于号
{
token.push_back(ch); // 将'='后面的'='存入token中
code = TK_EQ; // 单词为"=="
}
else
{ // = 赋值运算符
code = TK_ASSIGN; // 单词为"="
fseek(fp, -1L, SEEK_CUR); // 将超前读取的字符重新读取
}
}
break;
case '!':
{
ch = fgetc(fp); // 超前读取'!'后面的字符
if (ch == '=') // !=不等于号
{
token.push_back(ch); // 将'!'后面的'='存入token中
code = TK_LEQ; // 单词为"!="
}
else
{ // 其他字符
code = TK_UNDEF; // 未定义字符
fseek(fp, -1L, SEEK_CUR); // 将超前读取的字符重新读取
}
}
break;
case '<':
{
ch = fgetc(fp); // 超前读取'<'后面的字符
if (ch == '=') //<=小于等于号
{
token.push_back(ch); // 将'<'后面的'='存入token中
code = TK_LEQ; // 单词为"<="
}
else
{ //<小于号
code = TK_LT; // 单词为"<"
fseek(fp, -1L, SEEK_CUR); // 将超前读取的字符重新读取
}
}
break;
case '>':
{
ch = fgetc(fp); // 超前读取'>'后面的字符
if (ch == '=') //>=大于等于号
{
token.push_back(ch); // 将'>'后面的'='存入token中
code = TK_GEQ; // 单词为">="
}
else
{ //>大于号
code = TK_GT; // 单词为">"
fseek(fp, -1L, SEEK_CUR); // 将超前读取的字符重新读取
}
}
break;
/*分界符*/
case '(':
code = TK_OPENPA; //(左圆括号
break;
case ')':
code = TK_CLOSEPA; //)右圆括号
break;
case '[':
code = TK_OPENBR; //[左中括号
break;
case ']':
code = TK_CLOSEBR; //]右中括号
break;
case '{':
code = TK_BEGIN; //{左大括号
break;
case '}':
code = TK_END; //}右大括号
break;
case ',':
code = TK_COMMA; //,逗号
break;
case ';':
code = TK_SEMOCOLOM; //;分号
break;
// 未识别符号
default:
code = TK_UNDEF;
}
print(code); // 打印词法分析结果
}
}
int main()
{
string filename; // 文件路径
FILE *fp; // 文件指针
cout << "请输入源文件名:";
while (true)
{
cin >> filename; // 读取文件路径
fp = fopen(filename.c_str(), "r");
if (fp != NULL) // 打开文件
break;
else
cout << "路径输入错误!请重试:"; // 读取失败
}
cout << "/=***************************词法分析结果***************************=/" << endl;
lexicalAnalysis(fp); // 词法分析
fclose(fp); // 关闭文件
SetConsoleTextAttribute(GetStdHandle(STD_OUTPUT_HANDLE), FOREGROUND_INTENSITY | FOREGROUND_RED | FOREGROUND_GREEN | FOREGROUND_BLUE); // 字体恢复原来的颜色
system("pause");
return 0;
}
Comments NOTHING